Achieving Multi-tenancy#
When providing a common platform for multiple tenants, we have to answer the questions 1) do we isolate workloads across tenants and, if so, 2) how do we properly do so? While we theoretically trust all of our application teams, we also expect to run potentially untrusted code from a variety of sources. Therefore, we strongly feel a proper amount of isolation is necessary.
Defining a Tenant#
Before moving too far, we need to define a "tenant". For the IT Common Platform, the definition of a tenant is very loose. It might be an entire team. Or an environment (prod vs dev). Or a single application. Or even an environment for a specific application (prod vs dev for an app). To us, as a platform team, we don't really care. We treat them all the same and give our application teams the choice on how they want to divide their workloads.
Each tenant gets its own Kubernetes namespace, its own manifest repository, and its own configuration (ED group authorization, authorized domains, log forwarding, etc.).
Soft vs Hard Multi-Tenancy#
Soft multi-tenancy separates the cluster amongst various tenants using very loose isolation. This might include only namespace separation, but will run workloads from multiple teams on the same nodes. While teams are unable to modify the workloads of other teams, noisy neighbor problems can affect the I/O or network performance. And, while container escapes have been very rare, we want to limit the blast radius if one were to happen. The biggest advantage is increased resource utilization and lower costs.
Hard multi-tenancy provides further isolation by treating each tenant as untrusted. This requires more complex node pool management or the introduction of virtual cluster configuration. While this provides the maximum amount of protection, it comes at the tradeoff of additional complexity and lower resource utilization.
For our platform, we have decided to use a hard multi-tenancy model, but are currently not utilizing any virtual cluster technology. By using the four tenets of multi-tenancy outlined below, we are able to gain a sufficient level of isolation and protection between tenants.
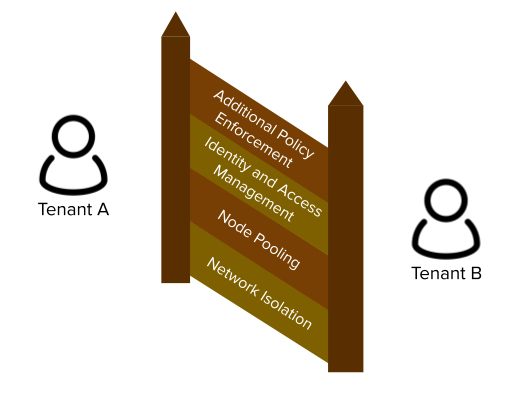
The Four Tenets of Multi-Tenancy#
The following four tenets describe the major components on making multi-tenancy work. While each can be done independetly of the others, they all need to exist in some form in order to sufficiently protect tenants and their workloads.
- Network Isolation - ensure applications can't talk to each other unless explicitly authorized to do so
- Node pooling - to reduce noisy neighbor problems, provide better cost accounting, and a greater security boundary, various pools of nodes should be used for tenants
- Identity and Access Management - tenants need the ability to both make changes in the cluster and query resources
- Additional Policy Enforcement - the built-in RBAC in Kubernetes provides a lot of support, but needs additional policy control to ensure tenants cannot step on each others' toes
Tenet #1 - Network Isolation#
For our platform, we want to limit the ability for rogue applications to directly interact with each other or negatively impact others. At the network layer, this means different tenants/namespaces can't reach each other directly within the platform environment. This allows a tenant to use supporting pods (such as databases and caches) that are network-accessible to their workloads, but inaccessible to other tenants.
In the case that one tenant needs to access the workloads from another, they are required to use an "out-and-back" approach. All of their network requests would exit the cluster, re-enter through the external load balancer, and be forwarded by the ingress controller to the right application.
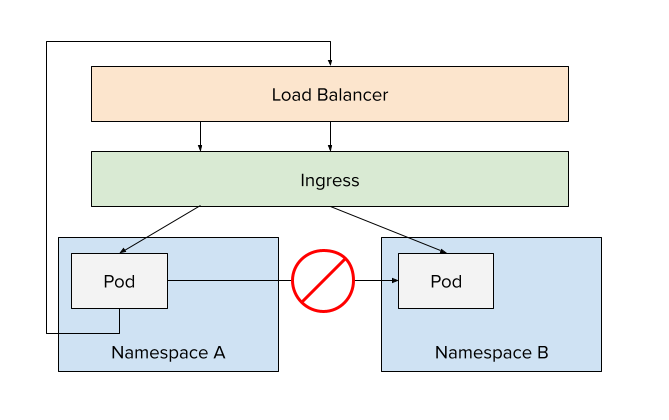
The only exception to this network policy our platform services. As an example, the Ingress controller obviously needs to send traffic across namespaces. The same would be true for a central Prometheus instance scrapping metrics from tenant applications.
Implementation#
Providing this level of network isolation depends on the specific CNI (Container Network Interface) being used. For us, we're using Cilium. With Cilium, we would simply define a network policy that restricts traffic across namespaces. The policy below denies all network ingress from namespaces that have the specified label (which is one we place on all tenant namespaces).
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "deny-other-tenants"
namespace: test-tenant
spec:
endpointSelector: {}
ingress:
- fromEndpoints:
- {}
ingressDeny:
- fromEndpoints:
- matchExpressions:
- key: k8s:io.cilium.k8s.namespace.labels.platform.it.vt.edu/purpose
operator: In
values:
- platform-tenant
This policy is applied per tenant within their namespace. We specifically chose to use an ingress rule to potentially allow tenants to define their own policies with a higher order that does allow traffic from namespaces (if the need ever arose). Had we chose to use egress rules, there's a chance a tenant creates an egress rule that starts flooding another tenant that isn't wanting the traffic.
Tenet #2 - Node Pooling#
As discussed earlier, there is a tradeoff between sharing nodes with multiple tenants and using isolated nodes per tenant. With higher security comes lower utilization and additional costs. One additional consideration we had to work with was cost accounting - how can we know how much each team/Banner fund was costing? To answer this question, we have decided to use multiple node pools. We have the flexibility to group tenants into a single node pool (e.g., put all of the ITSO/ITSL tenants together) or separate each tenant into a separate pool.
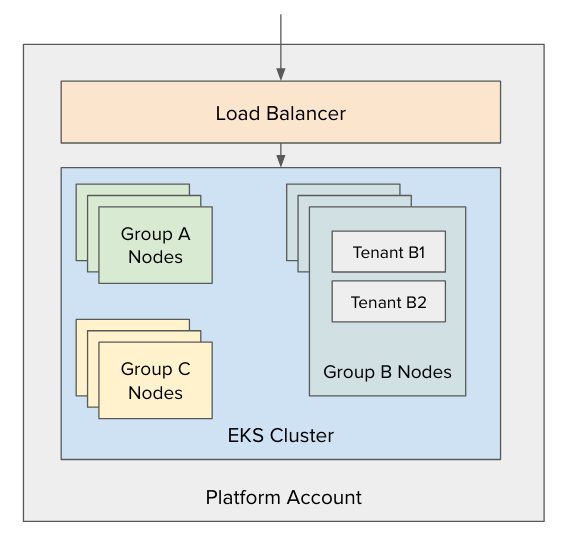
Defining the Node Pools#
We originally started with the Cluster Auto-scaler project. But, we ran into limitations…
- We needed to define many auto-scaling groups for each node pool
- How should we support EBS volumes? EBS volumes are tied to a specific AZ. If the CAS spins up a new node, there's no guarantee it'll end up in the correct AZ. This leads to a ASG-per-AZ approach, which quickly becomes a scaling nightmare.
- How can we support mixed instance types (some on-demand and some spot instances) and sizes?
- How can we reduce the amount of shared/"magic" names? The ASGs have been defined in one pipeline, far removed from where the tenant config itself was defined.
For us, Karpenter has been a huge benefit and we are actively migrating to it. While there are still a few shortcomings, it's super nice being able to define the node pools simply using K8s objects. The following Provisioner defines a simple node pool.
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: platform-docs
spec:
# Put taints on the nodes to prevent accidental scheduling
taints:
- key: platform.it.vt.edu/node-pool
value: platform-docs
effect: NoSchedule
# Scale down empty nodes after low utilization. Defaults to an hour
ttlSecondsAfterEmpty: 300
# Kubernetes labels to be applied to the nodes
labels:
platform.it.vt.edu/cost-code: platform
platform.it.vt.edu/node-pool: platform-docs
kubeletConfiguration:
clusterDNS: ["10.1.0.10"]
provider:
instanceProfile: karpenter-profile
securityGroupSelector:
Name: "*eks_worker_sg"
kubernetes.io/cluster/vt-common-platform-prod-cluster: owned
# Tags to be applied to the EC2 nodes themselves
tags:
CostCode: platform
Project: platform-docs
NodePool: platform-docs
While fairly straight forward, there are a few specific notes worth mentioning from this node pool's configuration...
- We specifically put taints on all tenant node pools so pods don't accidentally get scheduled on them without specifying tolerations (more on that in a moment)
- We tag the EC2 machines with various tags, including a few Cost Allocation Tags. The
CostCodeis a pseudo-organization level tag while theProjectis a specific project/tenant name. This allows us to use multiple node pools for the same organization. TheNodePoolisn't a cost accounting tag and only used for our own usage. - Since we are using the Calico CNI, we need to specify the clusterDNS address to support in-cluster DNS resolution.
Forcing Pods into their Node Pools#
Simply defining a node pool doesn't force tenants to use it. As a platform team, we don't want teams to have to worry about the pools at all. It would be best if it were completely invisible to them.
Using Gatekeeper's Mutation feature, we can define a policy that will mutate all pods in a tenant's namespace to add a nodeSelector and toleration, ensuring the pods are scheduled into the correct pool. And... it's done in a way that ensures tenants can't get around it. By using nodeSelectors, tenants can use the nodeAffinity config to provide Karpenter more configuration (to use spot instances, ARM machines, etc.).
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: it-common-platform-headlamp-nodepool-selector
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["it-common-platform-headlamp"]
location: "spec.nodeSelector"
parameters:
assign:
value:
platform.it.vt.edu/node-pool: platform-docs
---
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: it-common-platform-headlamp-nodepool-toleration
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["it-common-platform-headlamp"]
location: "spec.tolerations"
parameters:
assign:
value:
- key: platform.it.vt.edu/node-pool
operator: "Equal"
value: "platform-docs"
With this, all Pods defined in the it-common-platform-headlamp namespace will have a nodeSelector and toleration added that will force the Pod to run on nodes in the platform-docs node pool. If a pod starts up and there are no nodes, Karpenter will spin one up. It'll also automatically handle scale down as needed.
Tenet #3 - Identity Access and Management#
In order to run a successful platform, we want to ensure the platform team is not a bottleneck to the application teams in any way. They should be able to deploy updates or troubleshooting issues. As such, we want to give as much control back to the teams, but do so in a safe way.
Making Changes to the Cluster#
For our platform, we are using Flux to manage the deployments. Each tenant is given a "manifest repo" where they can update manifests and have them applied in the cluster. This prevents the need to distribute credentials for CI pipelines to make changes and treats the manifest repos as the source of truth for all desired state. This gives application teams control of the change management process, whether they want to push code out directly manually or through their CI pipelines or go through a secondary code review process. Flux also supports the use of webhooks, which we automatically apply to all of the manifest repos to get changes deployed very quickly without the need of a CI pipeline.
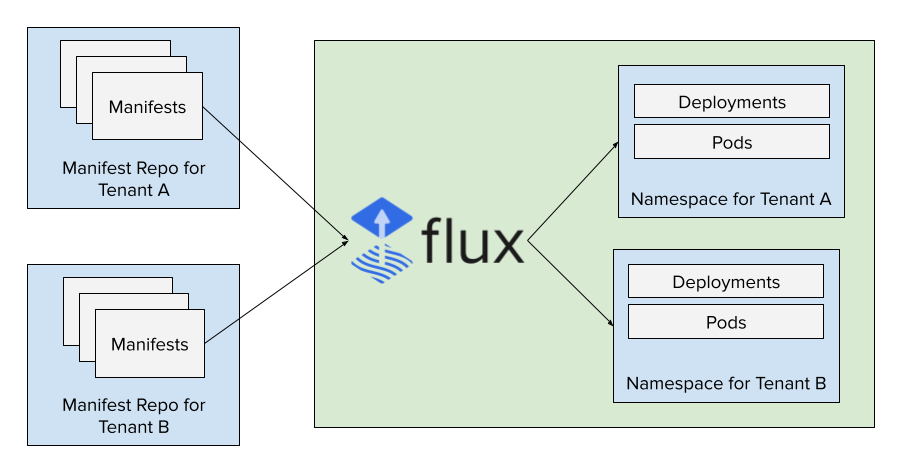
As a platform team, we only need to define a small amount of configuration to connect Flux to the manifest repo and tell it where to apply the manifests. For each tenant, we define a ServiceAccount specifically for Flux to use when applying the manifests. This ensures a tenant can't apply changes into any other namespace or create configuration that spans namespaces.
The following config creates the necessary resources to deploy Headlamp.
apiVersion: source.toolkit.fluxcd.io/v1
kind: GitRepository
metadata:
name: it-common-platform-headlamp
namespace: platform-flux-tenant-config
spec:
interval: 30m
url: ssh://git@code.vt.edu/it-common-platform/tenants/aws-prod/it-common-platform-headlamp
secretRef:
name: flux-ssh-credentials
ref:
branch: main
---
apiVersion: notification.toolkit.fluxcd.io/v1beta3
kind: Receiver
metadata:
name: it-common-platform-headlamp
namespace: platform-flux-tenant-config
spec:
type: gitlab
events:
- "Push Hook"
- "Tag Push Hook"
secretRef:
name: flux-webhook-token
resources:
- apiVersion: source.toolkit.fluxcd.io/v1
kind: GitRepository
name: it-common-platform-headlamp
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flux
namespace: it-common-platform-headlamp
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: flux
namespace: it-common-platform-headlamp
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flux-tenant-applier
subjects:
- name: flux
namespace: it-common-platform-headlamp
kind: ServiceAccount
---
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: it-common-platform-headlamp
namespace: it-common-platform-headlamp
spec:
interval: 1h
sourceRef:
kind: GitRepository
name: it-common-platform-headlamp
namespace: platform-flux-tenant-config
path: ./
targetNamespace: it-common-platform-headlamp
serviceAccountName: flux
prune: true
Providing Read-only Access to the Cluster#
To allow teams to troubleshoot and debug issues, we provide the ability for them to query their resources in a read-only manner. Recognizing that EKS comes with its own IAM-based auth, we needed a solution that would allow our tenants access without needing to enroll every user in our AWS account and works across multiple providers. We use Kubernetes built-in OIDC functionality to connect to the VT Middleware Gateway service.
We create RoleBinding objects that authorize specific ED groups to have read-only access to specific namespaces. We define a ClusterRole named platform-tenant that outlines the specific permissions they are allowed to utilize.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: tenant-access
namespace: example-tenant
subjects:
- kind: Group
name: oidc:sample-org.team.developers
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: platform-tenant
apiGroup: rbac.authorization.k8s.io
A big advantage of using Kubernetes OIDC is that we can share the OIDC tokens and allow users to configure their local Kubeconfig files with the same credentials, allowing them to use kubectl and other tools for additional querying. We make this functionality available via Headlamp.
Tenet #4 - Additional Policy Enforcement#
While the built-in Kubernetes RBAC provides a lot of capability, there are times in which we want to get more granular. A few examples:
- Tenants should be able to create Services, but how can we prevent them from creating NodePort or LoadBalancer Services?
- Tenants should be able to create Ingress/Certificate objects, but how do we limit the domains one tenant so they don't intercept the traffic meant for another?
- How can we enforce the Pod Security Standards to prevent pod from gaining access to the underlying host?
Fortunately, we can use admission controllers to plug in our own policies as part of the API request process. Rather than writing our own controller, we are using Gatekeeper to write Open Policy Agent policies. Using OPA, we can easily write unit tests to catch and prevent regressions.
Gatekeeper allows us to define ConstraintTemplate objects, which define a policy that accepts optional parameters. When defining a ConstraintPolicy, Gatekeeper creates a CustomResourceDefinition, allowing you to apply the policy. As an example, the following ConstraintTemplate is used to deny the creation of a Service with a spec.type of LoadBalancer.
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: blockloadbalancer
spec:
crd:
spec:
names:
kind: BlockLoadBalancer
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package block_loadbalancers
violation[{"msg": msg}] {
input.review.kind.kind == "Service"
input.review.object.spec.type == "LoadBalancer"
msg := sprintf("LoadBalancer not permitted on Service - %v", [input.review.object.metadata.name])
}
After applying this object, Gatekeeper allows us to create BlockLoadBalancer objects to actually apply the policy to various namespaces. In the snippet below, we apply this policy to the two specified namespaces.
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: BlockLoadBalancer
metadata:
name: landlord
spec:
match:
namespaces:
- it-common-platform-headlamp
- it-common-platform-docs
kinds:
- apiGroups: [""]
kinds: ["Service"]
In our other policies, we use parameters to provide additional input to the policy. This is useful to authorize specific namespaces to use specific hostnames for Ingress and Certificate objects.
Gatekeeper's mutation feature also enforces sensible pod defaults across all tenants: it automatically sets a default storageClass, configures securityContext.runAsNonRoot: true, drops all Linux capabilities (capabilities.drop: ["ALL"]), applies a seccompProfile.type of RuntimeDefault, and disables privilege escalation (allowPrivilegeEscalation: false). These defaults simplify provisioning and provide a more secure baseline.
Defining the Tenant Configuration#
While it feels like there's a lot to define for each tenant, it's very repetitive. Once we had defined a few tenants, we built a Helm chart that defines all of the various objects for each tenant, conveniently called the landlord. This landlord lets us provide a values file that defines the tenants, their config, and the node pools. An example values file is below. Today, the values for each cluster is stored in Git and applied using Flux.
Wrapping Up#
We recognize there is a lot of material described in this post. The fortunate thing is that there isn't much custom code or development needed to make it work as we're leveraging several open-source projects, most from the CNCF. As a quick run-through of those projects and their purposes, they are:
- Karpenter - node provisioner that simplifies the definition and deployment of node pools for tenants
- Gatekeeper - an admission controller that performs additional policy enforcement and provides mutation support to force pods into their correct node pool
- Flux - provides the GitOps automation pieces to apply manifests defined in the tenant manifest repos
In addition, the following repos contain our cluster configuration (all will require a valid VT login to access):
- Gatekeeper Policies - Helm chart that defines the Gatekeeper policies (using
ConstraintTemplateobjects) for policy enforcement - Landlord Chart - a Helm chart that provides the ability to define the environment for each tenant